

Heads up - this is a draft. Part of an experiment: publishing rough-but-timely versions of half-finished posts to a separate Drafts feed, instead of letting them rot in a folder while the tooling moves on without them. Expect: accurate commands, missing screenshots, and the occasional bit that needs a second pass. If you spot something to add, fix, or improve, let me know - I’d rather get it right than perfect.
How much time did your team waste this week searching for answers that already exist somewhere?
New engineer asks: “How does authentication work in our system?” PM asks: “Has anyone touched this API field before?” Support asks: “Where’s the documentation for this feature?”
And everyone does the same thing: searches Confluence, digs through Jira, posts in Slack, waits for someone who knows. Hours disappear into the void.
I’ve been experimenting a lot with NotebookLM for the past few months to solve exactly this problem. It’s not perfect - the UX is frustrating and file management is terrible - but it’s solving real problems I couldn’t solve easily before.
Here are 6 use cases you can copy, step-by-step.
Use Case #1: Tool Documentation Agents (Internal Help Desk)
The Problem (Before AI)
Your team uses Cursor, or Jira, or whatever internal tool. Someone new joins and can’t figure out how to configure something basic. They ask in Slack. Someone answers. Next week, someone else asks the same question. Repeat indefinitely.
Information is scattered across help docs, wikis, Slack threads nobody can find. Support burden falls on specific people who become bottlenecks. New team members take months to get up to speed because finding answers takes forever.
Only 12% of employees feel their organization does great onboarding. And here’s what kills me: 42% of workers say the knowledge they need is unique to their context. Generic documentation doesn’t cut it. You need something that understands YOUR tool stack.
The AI Solution
I’ve built agents for Cursor, NotebookLM, Claude code, Hex, Snowflake, internal tools - takes about 30-60 minutes once, saves hours every week. Here’s exactly how to do it.
STEP-BY-STEP WORKFLOW
1. Gather Documentation Links
Go to tool homepage and dev docs homepage
You need the parent page with the tree structure in the nav bar
Not individual pages - the main page that links to everything
2. Extract All Links
Install Link Klipper Chrome extension
Run it on the docs page
Exports a CSV of every link in the navigation
Takes about 30 seconds
3. Use my Agent Builder Bot
Link here → Prompt and agent builder
Use my “Agent Builder” on the ChatGPT Store
Tell it: “I’m building an agent for [tool name]”
Bot walks you through refinement
Type “ok, go” at any point for directions
4. Give Bot the Context
Upload the CSV of links
Say “that’ll be the context for the agent”
Bot rewrites the instructions to match
5. Upload to NotebookLM
Go to NotebookLM
Upload the markdown custom instructions from agent builder
This becomes your bot’s “personality”
6. Rename for Organization
Start filename with “A” or number + name
Example: “A-Cursor-Bot” or “01-Cursor-Documentation”
Why? NotebookLM sorting is absolute crap. This keeps it findable.
7. Upload Link CSV
Use NotebookLM’s link uploader
Upload the CSV of links
NotebookLM scrapes every link and adds as context
Takes a few minutes depending on how many pages
8. Test the Bot
Ask questions about the tool
Bot sources only from provided context
Provides direct URL links to help docs
Check that answers make sense
9. Share with Team
Create Google Group for access control
Share notebook with the group (group could also just be everyone in your company)
Everyone gets access to same knowledge base
Tools Used
Link Klipper (Chrome extension)
Agent Builder Bot (GPT Store)
NotebookLM (Google - free with Workspace)
Google Groups (sharing)
Why This Works
NotebookLM only sources from what you give it. That’s the key. It won’t make up answers or pull from the wider internet. You get citations with direct links. The team can maintain and update it centrally. And it’s free if you’re already using Google Workspace.
Here’s what makes this actually useful: new team members reach expert-level knowledge 4x faster when they have instant, sourced answers. Instead of 8 months to get up to speed, imagine 2 months. That’s not hype - that’s from actually watching people onboard with this vs without.
Time Savings
One-time setup: ~30-60 minutes
Ongoing: No support burden for common questions
Team finds answers instantly vs asking in Slack
The hidden time saver? You stop “explaining something to one person at a time.” When you find yourself answering the same question for the third time, that’s your signal to build this.
Gotchas & Lessons Learned
NotebookLM UX is terrible (I cannot stress this enough)
There exists chrome extensions now you can use for bulk deletion of source files
File management is crap - name files strategically
Multiple instruction sets possible (say “follow instruction set XYZ”)
Save really good answers as notes or they get deleted/lost
Pictures don’t get scraped and aren’t supported
Can’t have personal notes - sharing shows all notes to everyone
Use Cases
Cursor documentation bot (what I built first)
Internal tool help desks
Onboarding new team members
Reducing support ticket burden
Engineering tool documentation
Replication Guide
Find tool’s documentation homepage with nav tree
Install Link Klipper Chrome extension
Export CSV of all documentation links
Find “Agent Builder Bot” on GPT Store
Tell bot what tool you’re documenting
Provide CSV, let bot refine instructions
Upload bot’s markdown output to NotebookLM
Rename with A-prefix or number for sorting
Upload CSV to NotebookLM’s link uploader
Create Google Group and share notebook
Test with common questions your team actually asks
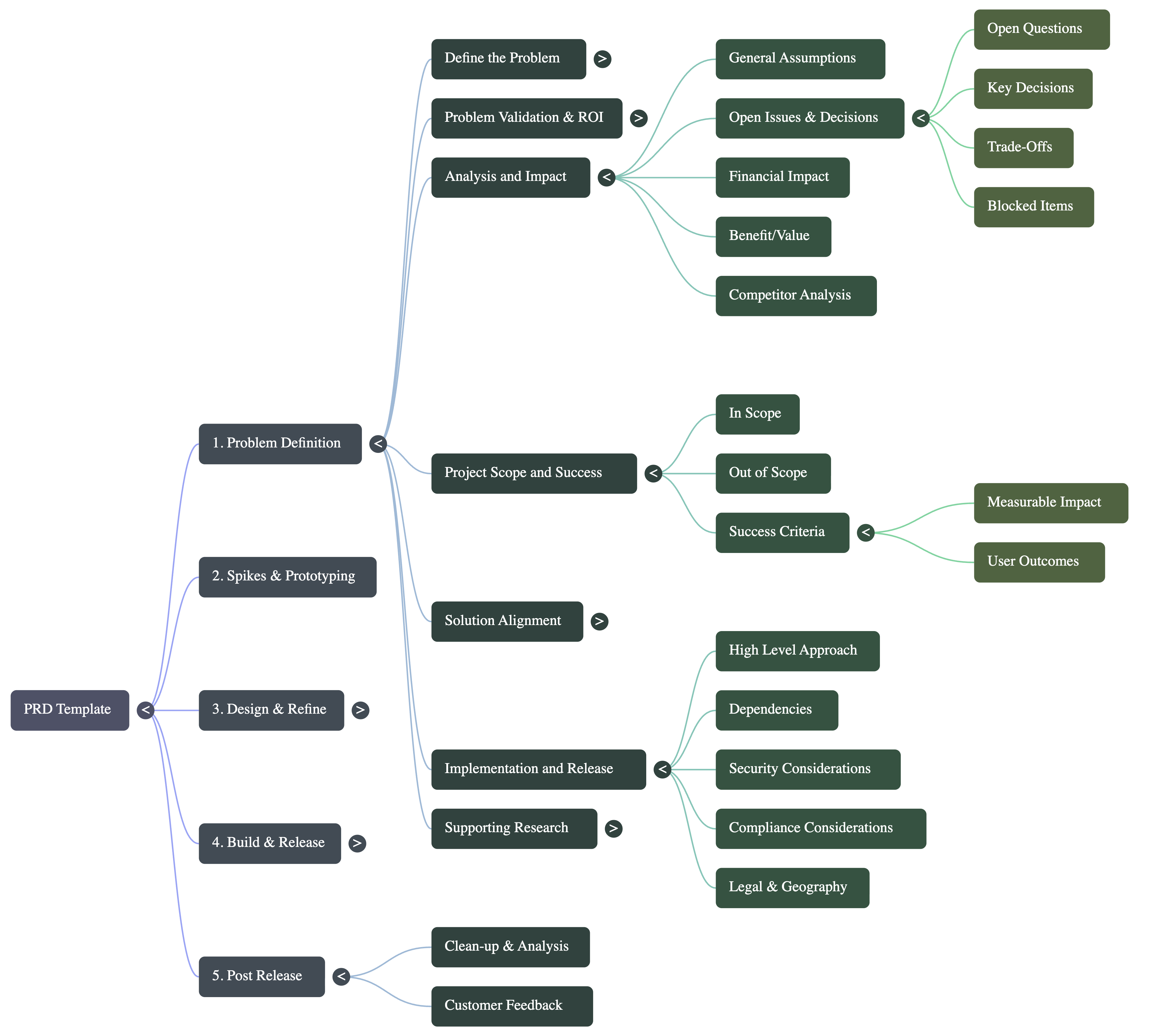
Use Case #2: Mind Map Project Discovery (Visual Navigation)

The Problem (Before AI)
You’re starting a complex project. Documentation is overwhelming. Stakeholders need different views of the same information. Leadership wants high-level overview. Engineering wants technical details. Product wants user journeys.
Information overload prevents quick understanding. You spend half your discovery time just helping people understand what you’re building.
I’ve found that product discovery typically takes 4 weeks minimum. But here’s what kills me: half that time is spent just helping people navigate what you’re building. Mind maps cut that navigation time dramatically.
The AI Solution
This one took me a while to figure out, but once I cracked it, I’ve used it on every major project since. You create multiple views of the same project - each optimized for different stakeholders.
STEP 1: Create Empty Template Structures
Ask AI (I use Cursor or ChatGPT) to generate empty documentation templates for different views:
Stakeholder-sensitive view (what leadership needs)
Salesforce stages view (what sales needs)
Actor-based view (who does what)
Team-based view (which team owns what)
MVP vs GA vs Future view (timeline phases)
Technical integration view (systems and APIs)
Journey flow template (step-by-step user flows)
The templates have headers only, no content. NotebookLM fills them from your actual project docs.
STEP 2: Upload Templates to NotebookLM
Create new NotebookLM project
Upload ALL empty templates as sources
Upload actual project documentation (user journeys, PRDs, discovery docs)
Everything goes into one notebook
STEP 3: Generate Mind Maps
Here’s the trick:
Turn OFF all sources except one empty template
Click “Generate Mind Map” in Studio
NotebookLM creates structured mind map from template headers
Mind map buttons are clickable and interactive
STEP 4: Activate Full Context
Turn ON all sources (templates + documentation)
Refresh the mind map
Now clicking any button pulls from full project context
Each click provides sources and citations from your actual docs
STEP 5: Share with Stakeholders
Different stakeholders use different template mind maps:
Sales team uses “Opportunity Stages View”
Engineering uses “Technical Integration View”
Leadership uses “Stakeholder-Sensitive View”
Everyone has same underlying source of truth
The “Knowledge Tree” Prompt
I’ve refined this prompt over multiple projects. Run it in NotebookLM with your context already loaded:
Generate a structured outline document titled "[PROJECT NAME] Knowledge Tree" that maps this project's complete scope for mind mapping. Start with the project name as the title, then organize hierarchically:
PROJECT TITLE: [Extract the main project/product/initiative name from the sources and use as: "PROJECT_NAME Knowledge Tree"]
1. PROJECT FOUNDATION
- Name, mission, core value
- Current status & future vision
- Key differentiators
- Success metrics
2. SCOPE & BOUNDARIES
- Geographic/market coverage
- Product/service boundaries
- Target segments
- Constraints & limitations
3. CORE OFFERINGS
- Main products/services
- Features & capabilities
- User journeys
- Technical specifications
[... continues through 10 sections ...]
Format with clear headers and bullet points. Include specific data, metrics, and examples. Create a single comprehensive document optimized for mind map conversion.
IMPORTANT: Use the main project/initiative name from the sources as the document title in format: "[PROJECT_NAME] Knowledge Tree"
Then:
Save output to note
Save note to source
Unselect all sources
Select only the new note source
Hit Mind Map button in Studio
Once complete, select all sources again
Mind map buttons now lead to full context sources
Tools Used
NotebookLM (Google)
Claude Code/Cursor (template generation)
Mind Map Studio (NotebookLM feature)
Why This Works
Multiple views of the same information. Interactive, clickable navigation. Reduces cognitive load. Sources are always cited. You can regenerate mind maps by simply changing template headers.
Here’s what I’ve found: knowledge grows better in stable, long-lived teams, but documentation still matters. The problem is traditional docs don’t provide different views for different audiences. Mind maps solve this - leadership gets their high-level view, engineers get their technical view, everyone’s looking at the same truth.
Time Savings
Creates comprehensive project overview in minutes vs hours
Stakeholders self-serve for information
Reduces “can you explain this again?” meetings
Leadership gets quick visual understanding
Those “walk me through the project” meetings that take 30-60 minutes? Cut to 10 minutes with a mind map walkthrough. And stakeholders can explore on their own instead of booking your calendar.
Gotchas & Lessons Learned
Must turn off sources before generating mind map from template (this confused me for days)
Template headers drive mind map structure - choose carefully
Can regenerate by simply editing template headers
NotebookLM file management is still terrible
Use Cases
Any project that requires documentation
User journey visualization
Complex feature documentation
Cross-functional project coordination
Product discovery presentations
Replication Guide
Use AI to generate 5-7 empty template structures (different views)
Create NotebookLM project
Upload all templates as sources
Upload project documentation
Turn off all sources except one template
Generate mind map in Studio
Turn all sources back on (except for the templates)
Use “Knowledge Tree” prompt for comprehensive view
Share different mind maps with different stakeholders
Use Case #3: Issue Investigation & Root Cause Analysis
The Problem (Before AI)
API field breaks in production. You need to find out if anyone touched this field before. Could be in any Jira ticket across years of history. Manual search takes hours or days.
Context is spread across multiple tickets. Hard to trace change history. You end up Slacking people: “Hey, did you work on this?” And waiting. And waiting.
Google’s SRE research emphasizes that postmortems should “fix systems and processes,” not just address symptoms. But you can’t fix the system if you don’t understand the full context of what happened. And that context is usually buried in tickets from 6 months ago that nobody remembers.
The AI Solution
I built a Python script for this (well, Cursor built it for me). Now I can find root cause in minutes instead of days.
WORKFLOW
1. Python Script Export (Done in Cursor/Claude code)
Script exports keywords from Confluence and Jira
Based on your search criteria
Example: Search for specific API field name
I run this script anytime something breaks
2. Generate Context File
Script creates single MD file
Contains all Jira tickets mentioning that field
Includes all Confluence pages with context
One file with everything relevant
3. Drop into NotebookLM
Upload MD file as source
Ask: “My team is having difficulty with [API field], can you help?”
NotebookLM searches all tickets
4. Get Root Cause
NotebookLM finds relevant tickets
Provides sources (links to specific Jira tickets)
Shows: “In this ticket, XYZ changed this field, which caused this validation error you’re seeing”
Direct links to dig deeper
5. Incredibly Fast Discovery
Root cause identified in minutes
Can see pattern across multiple tickets
Historical context nobody remembers
Alternative Approach: Full Jira Export
Don’t want to build a script? Here’s the lazy version that still works:
Export entire Jira filter to PDF
Drop PDF into NotebookLM
Now have every Jira ticket your company has ever done
Ask: “Has anyone touched this field?”
NotebookLM searches everything with sources
Tools Used
Python script (custom, built in Cursor)
NotebookLM (Google)
Jira export (PDF)
Why This Works
Searches historical context impossible to remember. Provides sources and citations, not just answers. Much faster than manual Jira searches. Can export entire Jira history. Sources only from your data - no hallucinations.
You’ll “never, ever again debug or understand this code as well as you do right now, with your original intent fresh in your brain.” But when you’re investigating an issue weeks or months later, you’ve lost that context. This approach gives you back the original context through historical tickets.
Time Savings
Root cause in minutes vs hours/days
No need to ask “who worked on this?”
Historical context instantly accessible
Reduces debugging time significantly
Stack Overflow research shows that teams with rapid feedback loops find more than 80% of bugs quickly. But what about the bugs that slip through? Those are the ones hiding in historical context. This workflow helps you find them fast.
Gotchas & Lessons Learned
Python script is custom (build once, reuse forever)
Jira filter export works for entire history
Keep exports updated periodically (I do monthly)
NotebookLM handles large PDFs well
Use Cases
API field troubleshooting (my most common use)
Bug investigation
Feature change history
“Who touched this last?” questions
Understanding legacy decisions
Replication Guide
Build Python script (or use Cursor/Claude to generate)
Script exports keywords from Jira/Confluence
Or: Export Jira filter to PDF for full history
Upload to NotebookLM
Ask questions about specific fields/issues
Get sources with direct links to tickets
Use Case #4: Architecture Validation & Feasibility Checks
The Problem (Before AI)
New feature requirements might conflict with existing architecture. You need to validate against system documentation. Don’t want to break existing patterns. Manual review takes significant time.
You can’t just “ask the person who built it” if they’ve moved on or if the system has evolved. And reading through 50 pages of architecture docs to check one thing is nobody’s idea of a good time.
The AI Solution
This one saves me from making architectural mistakes before they happen.
WORKFLOW
1. Load System Documentation
Upload architecture docs to NotebookLM
Include coding standards
Tech choice standards
Existing system design docs
All in one notebook
2. Upload New Requirements
Add new feature PRD or spec
Or just paste requirements as a note
3. Ask Validation Questions
“Does this requirement fit our architecture?”
“Can you suggest any changes we might need?”
“What patterns should we follow for this?”
4. Get Conflict Analysis
NotebookLM identifies conflicts
Suggests architectural changes
Example: “You need an extra event here, you need a new consumer for that event”
Shows whether you can extend existing vs create new
Why This Works
NotebookLM sticks religiously to sources. Can ask it to suggest changes (it breaks out of constraints when you ask). Provides specific recommendations. Sources all suggestions from your docs. Prevents architectural drift.
Product discovery research emphasizes validating whether solutions are “usable, useful, and feasible” - this workflow handles the “feasible” part by checking against your actual system architecture, not theoretical constraints.
Tools Used
NotebookLM (Google)
System documentation (architecture, coding standards)
Time Savings
Feasibility check in minutes vs hours
Prevents architectural mistakes early
Reduces back-and-forth with architects
Catches conflicts before development
You’re not just saving time - you’re creating shared understanding. When the validation comes from your own architecture docs (with citations), there’s no argument about whether it fits or not.
Use Cases
New feature validation
Architecture review
Tech stack alignment
Coding standards compliance
Replication Guide
Upload system documentation to NotebookLM
Upload new requirement/PRD
Ask: “Does this fit our architecture?”
Ask: “Can you suggest changes needed?”
Review suggestions against sources
Use for early validation before development
Use Case #5: Historical Context Search (”Has Anyone Touched This?”)
The Problem (Before AI)
Need to know if specific field or feature was discussed before. Information buried in old Jira tickets. Can’t remember who worked on what. Need quick context for decisions.
Only 4% of companies consistently document their processes. The rest rely on tribal knowledge and scattered tickets. When someone leaves or moves teams, that knowledge evaporates.
The AI Solution
This is basically Use Case #3 but broader. Same script, different questions.
WORKFLOW
1. Export Full Jira History
Export Jira filter to PDF (print details button when In a filter search)
Can export entire company history (yes, really)
One-time effort per quarter or whatever
2. Upload to NotebookLM
Single upload of all tickets
Takes a while first time
Worth it
3. Ask Questions
“Has anyone touched this field?”
“What tickets mention [feature]?”
“Who worked on [system]?”
Any question about your project history
4. Get Sourced Answers
NotebookLM finds all relevant tickets
Provides direct links
Shows context from each ticket
No more digging through Jira manually
Alternative: Keyword-Based Export
Use Python script (Use Case #3)
Export only tickets matching keywords
Smaller, more focused context file
Faster searches
Tools Used
Jira export (PDF)
NotebookLM (Google)
Python script (optional, for keyword filtering)
Why This Works
Company memory in searchable format. Sources with direct links. Faster than manual Jira searches. No hallucinations - only from your tickets.
If you’re explaining something to one person at a time, you need a better system. This is that system. Your entire team’s history, searchable with citations.
Time Savings
Find historical context in seconds
No need to ask team members
Reduces “who worked on this?” Slack messages
Those Slack interruptions where someone asks “Hey, did we ever discuss [X]?” - they disappear. Team members find their own answers, sourced from actual tickets, without disrupting anyone’s flow.
Replication Guide
Export Jira filter to PDF (or use keyword script)
Upload to NotebookLM
Ask questions about fields/features/history
Get sourced answers with ticket links
Use Case #6: Stakeholder Directory & Team Context
The Problem (Before AI)
New to project or team. Don’t know who owns what. Need to understand team structure. Stakeholder personas unclear.
Only 12% of employees feel their organization does great onboarding. When you’re new to a project, figuring out “who should I talk to about X” can take weeks. This shortens it to minutes.
The AI Solution
I built this for a project of mine when I realized I couldn’t keep track of which team owned what.
WORKFLOW
1. Create Stakeholder Documentation
Document team structure
Roles and responsibilities
Stakeholder personas
Who owns what systems
2. Generate Mind Map (Use Case #2 method)
Create team-based view template
Upload to NotebookLM with team docs
Generate mind map
3. Navigate by Team/Persona
Click “Operations” → see Operations team context
Click “Ops Analyst” → see persona details
Click “Ops Manager” → see manager persona
All sourced from your docs
4. Search for Context
Ask about specific teams
Get sourced information
Understand relationships
Tools Used
NotebookLM
Mind Map Studio (NotebookLM feature)
Stakeholder documentation
Why This Works
Visual directory of people and teams. Searchable team context. Onboarding new team members. Quick reference for cross-functional work.
Knowledge retention works best in stable teams, but you still need to understand who does what. Communities of practice help, but they require active participation. This gives you passive access to team context whenever you need it.
Time Savings
Instant access to team information
Reduces “who should I talk to?” questions
Faster onboarding
New team members reach expert knowledge 4x faster when they have instant access to “who knows what” without having to ask around. This is how you do that.
Replication Guide
Document stakeholder/team information
Create team-based view template
Upload to NotebookLM with team docs
Generate mind map
Share with team for quick reference